Présentation de la chaîne de traitement
Ce document est publié librement sur le web à destination de la communauté scientifique dans le cadre de la licence Creative Commons « Paternité-Pas d’Utilisation Commerciale-Partage des Conditions Initiales à l’Identique 2.0 France ». En accord avec cette licence, si vous utilisez ce document dans vos travaux, vous êtes prié de mentionner sa référence (Programme PRESTO, titre, auteur(s), lien URL).
![]()
Rédaction : Denis Vigier
http://www.icar.cnrs.fr/membre/dvigier
denis.vigier@ens-lyon.fr
Chaîne de traitement PRESTO
1. La tokenisation dans Presto
Le processus de tokenisation dans Presto s’est déroulé en trois étapes successives, la sortie de l’étape n-1 constituant l’entrée de l’étape n.
Étape 1. Il a d’abord été procédé à une tokenisation « maximale » du corpus en ceci que les caractères séparateurs utilisés1 ont été uniquement traités comme tels, sans considération pour leur rôle de « composant » possible. Autrement dit, carte bleue a été segmenté en deux tokens, aujourd’hui en trois (aujourd | ’ | hui), etc. Une des difficultés rencontrée à la sortie de cette première étape est à mettre en rapport avec la grande variété des graphies au XVIe s., certains mots pouvant contenir dans leur graphie un voire plusieurs caractères séparateurs. Le lemme <naguère>2 est un bon exemple, qui possède dans Presto les graphies suivantes: naguère, naguére, naguiere, naguieres, nagyères, n’aguere, n’agueres, n’aguères, n’aguiere, n’aguieres, n’a gueres3. À l’issue de l’étape 1 de la tokenisation, ces formes ont donc été segmentées en un (naguére, …), trois (n’aguere, …) voire quatre tokens (n|’|a|gueres) alors qu’elles doivent être rattachées à un seul lemme. Il nous a donc fallu effectuer un contrôle manuel de la tokénisation et en particulier de la fusion des tokens. Ce contrôle a été introduit en phase finale après l’annotation automatique par TreeTagger (H. Schmid, 1994).
Étape 2. Une nouvelle segmentation à partir de règles spécifiques a ensuite été appliquée. Celles-ci mettaient en jeu des listes de mots établies par l’ingénieur du projet (Achille Falaise) à partir du principe de segmentation ainsi défini :
Une unité graphique est segmentée en plusieurs unités ssi cette unité se présente uniquement sous forme segmentée en français moderne
Exemple :
La forme moymesme courante au XVIIe s. a été segmentée. De même, les formes adjectivales et adverbiales, très courantes au XVIe s., où l’adverbe tres est accolé à l’adjectif (trecher, tresdoux, tresrude, … ) ou à l’adverbe (tresdoucement, …) qu’il modifie ont été segmentées.
- trescher amy Antire, Pour te vouloir mon intention dire, J’ay desormais deliberé (…) (M. Scève, Saulsaye, 1547)
- tresdouce richesse ! Heureux repos eslongné de tristesse, Qui en Yver, Printemps, Automne (…)(M. Scève, Saulsaye, 1547)
- (…) dont le desir tresdoucement me mord. (M. Scève, Saulsaye, 1547)
Remarque :
Les formes ledit, notredit, votredit etc. déterminant composé en ancien français ont été considérées comme appartenant au paradigme du déterminant composé défini « ledit ».
Étape 3. Enfin, une étape de fusion automatique de tokens a été appliquée, s’appuyant sur l’algorithme dit « longest matching » ou « longest match« 4 (N. Y. Liang, 1986) et sur le lexique Presto (présenté infra). Cet algorithme a ainsi permis par ex. de réunir les trois tokens obtenus à l’issue de l’étape 1 pour le mot « aujourd’hui » car le lexique Presto possédait la forme « aujourd’hui » (de même que la forme « hui » mais la règle qu’on peut traduire par « la plus longue chaîne d’abord » a conduit l’outil à sélectionner préférentiellement la forme « aujourd’hui »). En revanche, comme notre lexique ne contenait pas les formes n’aguere, n’agueres, n’aguères, n’aguiere, n’aguieres, n’a gueres, celles-ci n’ont pas été reconnues et ont donc dû subir un post-traitement (voir phase de contrôle manuel infra).
2. Annotation morphosyntaxique et lemmatisation dans Presto
On présente d’abord un tableau général des grandes étapes du processus d’annotation suivies dans Presto puis on évoque le jeu d’étiquettes utilisé.
2.1 Étapes du processus d’annotation
Campagne d’annotation manuelle par des experts portant sur la période du XVIe s. au XVIIIe s. À l’issue du processus de tokenisation, une phase d’annotation manuelle d’une fraction du corpus Presto (sous-corpus dit « gold standard » : 5 textes échantillonnés, 62.000 tokens) a été accomplie en juillet-août 2014 par trois annotateurs experts distincts. Une partie des tokens avait préalablement été pré-annotée automatiquement par projection du lexique Presto sur le corpus, suivie d’une étape de désambiguïsation automatique, cela afin de faciliter le travail des annotateurs. L’environnement informatique choisi pour cette annotation manuelle a été le logiciel Analog conçu et développé par M.-H. Lay (Université de Poitiers) qui a participé à cette campagne. Cet outil permet d’éditer les corpus annotés (M.-H. Lay & B. Pincemin, 2010). Toutes les occurrences d’une erreur détectée sont localisées à l’aide d’un concordancier. La modification (correction) effectuée sur le résultat de la concordance porte en un seul temps sur toutes les occurrences similaires.
Entraînement de l’outil TreeTagger. À l’issue de cette campagne d’annotation, une fraction (80%) du sous-corpus « gold standard » ainsi que le lexique Presto construit parallèlement (voir infra) ont permis d’entraîner l’outil TreeTagger qui, à partir du « modèle de langage » qu’il a lui-même construit, a pu annoter automatiquement (étiquetage morphosyntaxique et lemmatisation) l’intégralité du corpus.
Phase de contrôles manuels. À l’issue de cette étape, plusieurs post-traitements ont été appliqués : certains avaient trait à la fusion de tokens, d’autres à leur segmentation. D’autres enfin visaient à corriger des erreurs diverses (erreurs de segmentation, lemmes erronés, …).
Nous allons nous arrêter sur les étapes de fusion et de segmentation.
Contrôle manuel pour la fusion des tokens : nous nous sommes adossés aux trois principes de décision suivants :
Principe 1 Une séquence de 2 unités graphiques (UG) est fusionnée ssi une au moins des unités qui la forme ne peut être traitée comme une unité linguistique car on ne dispose pas d’étiquette morphosyntaxique possible pour elle, quel que soit l’état de langue considéré. La recherche d’une telle étiquette doit être conduite manuellement en s’appuyant sur les dictionnaires de langue suivants : Tobler-Lommatzsch, DMF, Dict. Huguet, Dict. de l’Académie (1ère éd. 1694, 4ème éd. 1762), TLFi. Cette fusion doit être réitérée jusqu’à ce qu’on aboutisse à une unité linguistique dotée d’une étiquette.
Pour appliquer ce principe, on recherche d’abord dans le corpus tokenisé les unités qui ne disposent pas, après projection du lexique Presto (voir infra), d’étiquette morphosyntaxique. On applique alors manuellement les principes de décision. Les tokens identifiés comme devant être fusionnés sont ensuite intégrés dans une liste pour un traitement automatique sur tout le corpus.
Voici deux exemples.
La segmentation de parce que en deux tokens aboutit à l’UG parce à laquelle on ne peut assigner aucune étiquette morphosyntaxique. Diachroniquement, cette unité résulte d’une fusion graphique de la préposition par et du pronom ce. Ici, deux positions seraient théoriquement possibles : on segmente parce en deux tokens [lemmes : <par> <ce> <que>5] ou on fusionne parce que en un seul token. Il a été choisi de fusionner.
Autre exemple : il a été vu supra que les graphies normalement rattachables au lemme <naguère> (naguère, naguére, naguiere, naguieres, nagyères, n’aguere, n’agueres, n’aguères, n’aguiere, n’aguieres, n’a gueres) ont été, à l’issue de l’étape 1 de la tokenisation, segmentées en un, trois ou quatre tokens.
Soient d’abord les graphies segmentées en trois tokens. Les unités graphiques « aguere | agueres | aguères | aguiere | aguieres » ne se voient attribuer aucune étiquette morphosyntaxique dans les dictionnaires cités. La fusion opérée avec l’apostrophe qui précède n’aboutit pas à une UG étiquetable. Elle est donc réitérée jusqu’à aboutir aux formes graphiques n’aguere, n’agueres, n’aguères, n’aguiere, n’aguieres dont la consultation de dictionnaires attestent l’existence6.
Enfin, dans le cas de la séquence graphique n’a gueres, seule la fusion entre les tokens initiaux <n> et <’> est opérée comme partout ailleurs dans le corpus (variante graphique de ne). Dès lors, les tokens <n’> <a> <gueres> reçoivent tous une étiquette morphosyntaxique après projection du lexique Presto : <Rp> <Vuc> <Rg>. Aucune fusion n’a donc été opérée.
Doit-on s’alarmer du fait que la graphie n’a gueres n’ait ainsi pas été rattachée au lemme <naguère> ? Nous nous en réjouissons au contraire. En effet, si un linguiste se saisit de l’idée d’étudier dans Presto le processus de figement (aboutissant à une agrégation des constituants initialement distincts) dont a été le siège cet adverbe, il retrouvera nécessairement sur sa route (c’est-à-dire dans sa concordance, pourvu qu’il examine – mais comment pourrait-il en être autrement ? – la séquence de lemmes <ne> <avoir> <guère>) la graphie en question (n’a gueres). Ce sera alors à lui de se prononcer sur le caractère figé de la séquence : nous ne l’aurons pas fait à sa place.
Principe 2 : On fusionne les séquences d’unités graphiques formant un nom propre dont l’orthographe moderne présente toujours une seule unité graphique.
Par exemple, Ménil-montant pour Ménilmontant
Principe 3 : Les séquences de la, de l’, dans les emplois où nous les avons analysés comme des variantes de l’article partitif DU actualisant des noms massif, ont été fusionnées.
Contrôle manuel pour la segmentation des tokens : à ce stade, le contrôle a porté, outre sur les erreurs de segmentation, sur les amalgames. Pour la période 1501-1944 couverte par le corpus, les seuls amalgames rencontrés concernaient les cas de préposition (de, à, en) suivi d’un article défini (le, les) ou d’un déterminant / pronom relatif (duquel, auquel, esquels, …)7. La segmentation de ces amalgames était cruciale pour travailler sur les prépositions, en particulier pour explorer avec nos outils leurs contextes distributionnels. Cette segmentation n’a cependant pas été intégrée dans le processus automatisé initial de tokenisation du corpus, mais introduite dans une phase plus tardive.
La construction du lexique Presto
La tokenisation et l’annotation du corpus ont nécessité à plusieurs reprises l’intervention du lexique Presto. Voici les grandes étapes qui ont présidé à sa construction.
Étape 1. Lexique de départ. Ce lexique, constitué de triplets lemme-forme-catégorie, a été élaboré pour sa plus grande part par G. Souvay. La ressource initiale sélectionnée a été le lexique Lefff (Lexique des Formes Fléchies du Français, B. Sagot : 2010). Puis ont été ajoutés à ce lexique, lorsqu’ils étaient manquants, des triplets lemme-forme-catégorie issus du logiciel Morphalou (http://www.cnrtl.fr/lexiques/morphalou/LMF-Morphalou.php, L. Romary, A.-S. Salman, G. Francopulo, 2004) dont les données sont tirées du TLF (Trésor de la Langue Française, http://atilf.atilf.fr), des triplets issus du DMF (Dictionnaire du Moyen Français, http://www.atilf.fr/dmf) et d’autres enfin tirés des lexiques morphologiques liés au lemmatiseur LGeRM (lemmatisation de la variation graphique des états anciens du français et lexiques morphologiques, Souvay & Pierrel, 2009). Des ajouts complémentaires ont été effectués par G. Souvay à partir d’autres lexiques plus spécialisés.
Étape 2. Étant donné que nous avions réunis des lexiques d’origines très différentes, nous avons mis en œuvre une phase de conversion des étiquettes morphosyntaxiques utilisées dans ces lexiques en vue de les rendre compatibles avec le jeu d’étiquettes Presto défini pour le projet. De même, une étape de normalisation des lemmes a été réalisée.
Étape 3. Le lexique ainsi obtenu a ensuite été « archaïsé » en vue de couvrir au mieux l’extrême variété des formes graphiques qu’on trouve dans les textes notamment du XVIe s. Pour ce faire, nous avons recouru à une sélection de règles élaborées par G. Souvay et issues du système LGeRM. Le tableau suivant, adapté de S. Diwersy, A. Falaise, M.-H. Lay & G. Souvay (2017 : 34) présente, en guise d’illustration, les règles appliquées pour produire dans le lexique des formes (tokens) « archaïques » pour des lemmes terminés par la séquence de caractères -uit, comme fruit
| Règles [R] utilisées | Formes produites | |
| R1 | si (finale (lemme) est UIT) alors UIT → UICT | fruict, fruicts |
| R2 | si (finale (lemme) est UIT) alors UITS → UIS | fruis |
| R3 | si (S en finale) alors S → Z | fruitz |
| R4 | I → Y | fruyt, fruyts |
Ces règles, itérées trois fois, ont été systématiquement appliquées aux formes issues de l’itération précédente. Ainsi la deuxième application de la règle 3 [R3] aux formes issues du tableau ci-dessus donne les (nouvelles) formes fruictz, fruiz, fruytz et de la règle 4 donne fruyct, fruycts, fruys. Une dernière itération produit les formes fruyctz, fruyz. Au final, au lemme <fruit> sont donc affectées dans le lexique Presto les formes fruict, fruicts, fruis, fruitz, fruyt, fruyts, fruictz, fruiz, fruytz, fruyct, fruycts, fruys, fruyctz, fruyz. Bien entendu, cette procédure d’archaïsation génère immanquablement des formes inexistantes dans le corpus. Mais il s’agit là d’un inconvénient mineur au regard de l’extension de la reconnaissance des formes qu’elle permet, comme l’illustrent S. Diwersy, A. Falaise, M.-H. Lay & G. Souvay (2017: 35) en appliquant le lexique Presto sur le corpus Frantext (tranche 1451- 1751) :
Le lexique Presto comporte ainsi actuellement environ 3 200 000 entrées pour un lexique de départ comportant 450 000 entrées. Environ 2 000 règles d’archaïsation ont été utilisées. La figure [suivante] montre le gain en termes de couverture lexicale de l’archaïsation. L’analyse des lacunes du lexique montre une forte proportion de noms propres et de mots étrangers (essentiellement les mots latins). En termes de graphie on remarque une forte proportion d’hapax. Il s’agit souvent de variantes exotiques ou d’erreurs (numérisation, rupture de mots, impression).
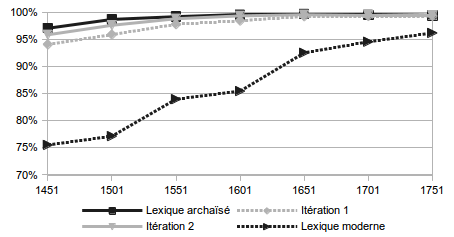
Figure 1 Couverture du lexique Presto sur le corpus Frantext avant archaïsation (lexique moderne), après archaïsation (lexique archaïsé), et étapes intermédiaires (itérations 1 et 2).
Étape 4. Vient ensuite une phase de recherche des lemmes et des formes inconnus. Le logiciel LGeRM analyse ces dernières en appliquant cette fois toutes les règles morphologiques dont il dispose et effectue des hypothèses sur leur lemme de rattachement, hypothèse qui sont ensuite évaluées manuellement par ordre de fréquence décroissante.
Étape 5. Phase de normalisation manuelle des lemmes : il s’agit d’appliquer à tout le lexique les mêmes conventions pour l’affectation d’un lemme à une forme donnée. Ces conventions ont fait l’objet d’une déclaration de règles qu’on trouvera dans l’ANNEXE 3. Lorsque le lemme est absent du lexique Presto, c’est le premier mot de l’entrée du TLFi qui est retenue, et si cette entrée n’existe pas, c’est le premier mot de celle du DMF et en dernier ressort, du Tobler-Lommatzsch.
Étape 6. Des contrôles manuels sont effectués sur le lexique, donnant lieu à des corrections et à des ajouts dans le lexique complémentaire.
Pour conclure, nous proposons de reproduire ci-dessous le schéma présenté dans S. Diwersy, A. Falaise, M.-H. Lay & G. Souvay (2015) qui récapitule la plupart des étapes évoquées ci-dessus (§ 2.1 et §2.2).
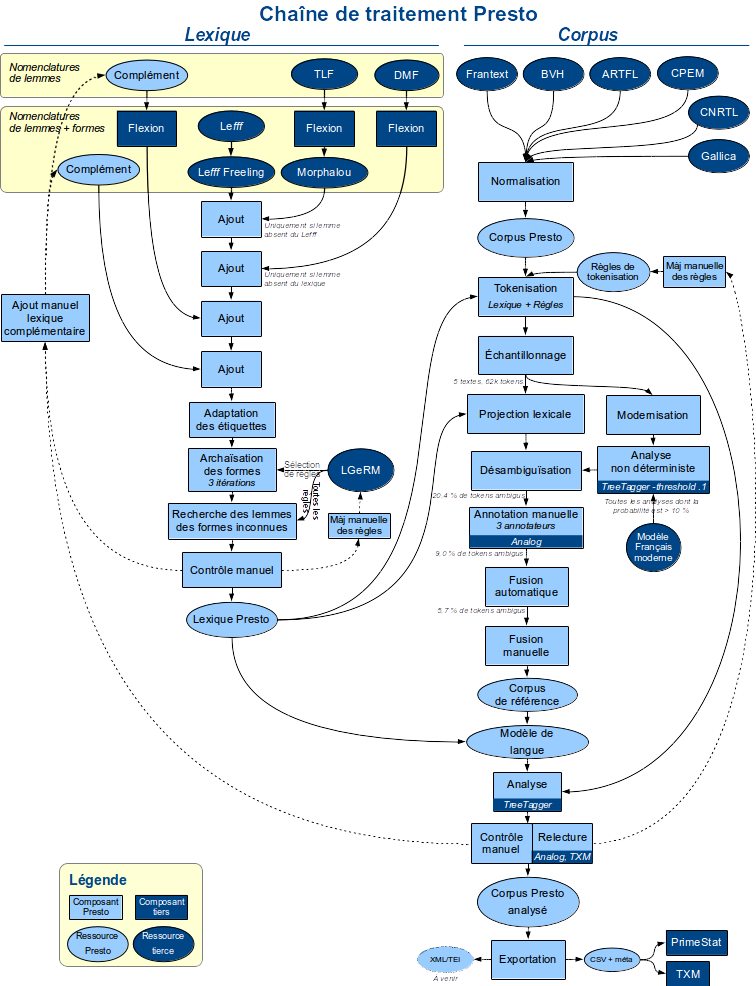
Figure 2 Chaîne de traitement utilisée dans le programme Presto.
[Rédacteur : Denis Vigier]
1 Dont voici la liste : ,;:.?!' »-«»()[]
2 Conventionnellement, nous plaçons entre chevrons les métadonnées relatives à la POS (part of speech/ partie du discours) et au lemme, ce dernier étant par ailleurs graphié en petites capitales.
3 « il m’escripvit n’a gueres qu’il estoit devenu patays » (1542, F. Rabelais, Gargantua)
4 Liang, N. Y. (1986) « On computer automatic word segmentation of written Chinese », Journal of Chinese Information Processing 1 (1).
5 Option adoptée par la BFM.
6 Concrètement, on interroge la base du Grand Corpus des dictionnaires (Classiques Garnier Numérique) qui réunit les 24 dictionnaires les plus importants consacrés à la langue française, soit près de 200 000 pages. La liste des dictionnaires est disponible en ligne dans les « Principes d’édition » de ce grand corpus.
7 L’annotation morphosyntaxique et la lemmatisation dans la BFM a dû en outre compter avec les phénomènes d’enclise absentes du corpus intégral Presto. Par ex. dans le cas du pronom relatif : enclise du pronom personnel précédé du pronom relatif : kil, quil (« ki / qui + le »), ques (« que + les »), kis, quis (« ki / qui » + les ») ; enclise du pronom adverbial précédé du pronom relatif : quin (« qui + en »); etc. Voir http://bfm.ens-lyon.fr/IMG/pdf/Cattex2009_manuel_2.0.pdf