Description du corpus
Ce document est publié librement sur le web à destination de la communauté scientifique dans le cadre de la licence Creative Commons « Paternité-Pas d’Utilisation Commerciale-Partage des Conditions Initiales à l’Identique 2.0 France ». En accord avec cette licence, si vous utilisez ce document dans vos travaux, vous êtes prié de mentionner sa référence (Programme PRESTO, titre, auteur(s), lien URL).
![]()
Rédaction : Denis Vigier
http://www.icar.cnrs.fr/membre/dvigier
denis.vigier@ens-lyon.fr
Description du corpus Presto
[Date de rédaction du document : 10_07_2018]
« Niveaux » et « Versions » du corpus Presto
Nous avons distingué trois niveaux dans le corpus : « noyau, contrôlé, étendu ». Ces trois niveaux sont de taille croissante. Le corpus « étendu », dont la taille est la plus grande, contient tous les textes du corpus noyau (taille la plus petite) et du corpus contrôlé (taille intermédiaire) – ainsi que d’autres textes. Le corpus contrôlé contient une partie du corpus noyau, et d’autres textes.
La figure suivante représente ces relations d’inclusion totale ou partielle.
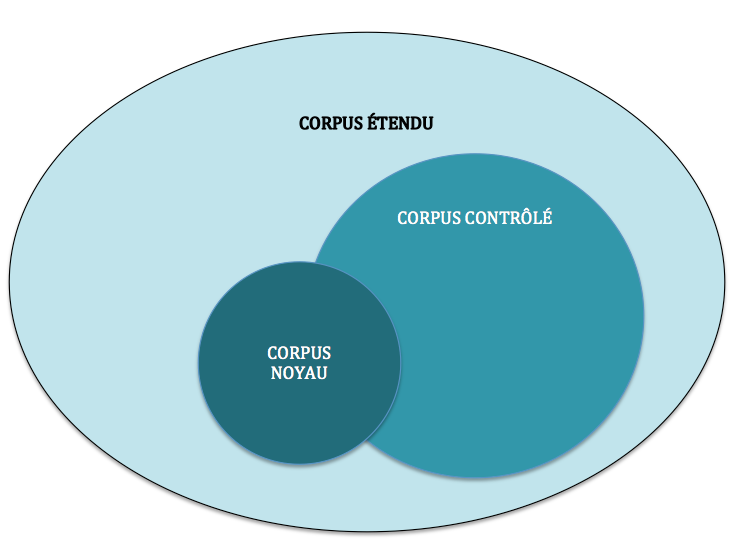
Chaque niveau se présente en outre sous deux versions : l’une regroupe les textes dans leur intégralité ; l’autre dans une version échantillonnée.
Corpus Noyau (= Presto_noyau )
Le corpus noyau réunit l’ensemble des œuvres mises à disposition de la communauté des chercheurs, soit 53 textes pour un nombre total de 6.820.161 mots (version intégrale) / 1.924.532 mots (version échantillonnée). Ces textes, sous licence libre, seront téléchargeables en version annotée ou non.
Corpus contrôlé (= Presto_contrôlé)
Le corpus « contrôlé », qui inclut le corpus noyau, est le niveau sur lequel a porté l’essentiel de nos efforts en matière de construction « raisonnée » du corpus (choix de la population cible, mise œuvre du critère de comparabilité, …). Il réunit actuellement 162 textes pour un nombre total de 11.636.573 mots (version intégrale) / 5.358.382 mots (version échantillonnée). Ces textes se répartissent par décennie comme suit :
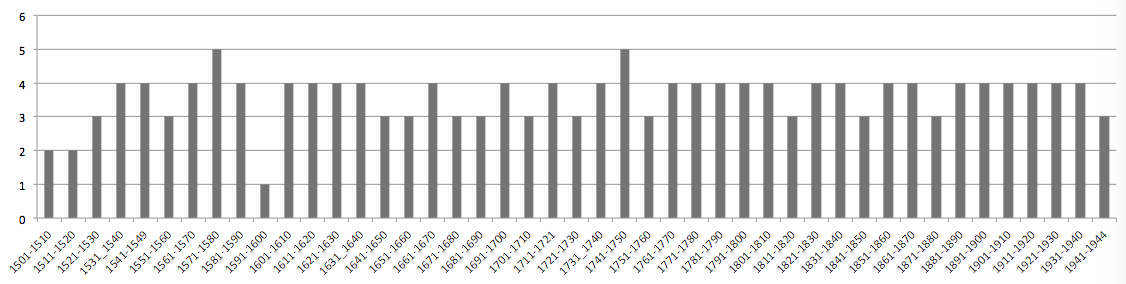
Cette répartition est relativement régulière ; les irrégularités les plus nombreuses figurent – comme on le devine aisément – dans la période la plus ancienne : 1501-1600.
Corpus étendu (= Presto_étendu )
Ce niveau du corpus réunit 315 textes pour un nombre total de 28.309.240 mots (version intégrale) / 11.002.199 mots (version échantillonnée). Y ont été agrégés selon les opportunités i) des textes relevant d’autres genres discursifs ii) des textes dont le statut juridique était indécis, l’ensemble permettant d’étoffer le corpus pour permettre des études plus précises sur certaines occurrences (mots, lemmes… motifs) dont on peut penser qu’elles sont peu nombreuses.
Voici la répartition des textes qu’on y observe pour la période 1501-1944 :
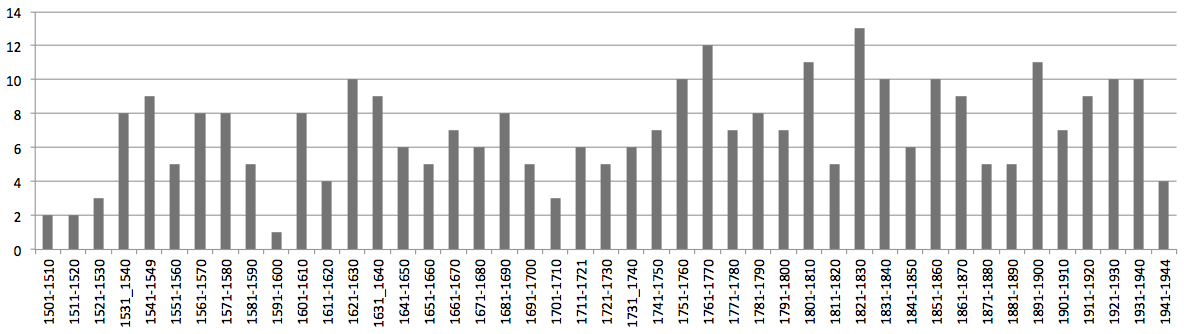
Le diagramme suivant permet de comparer la répartition des 162 textes de Presto_contrôlé et celle des 315 textes de Presto_étendu.

On observe à la fois le gain en nombre de textes (et de mots) que procure le niveau étendu du corpus, mais en même temps la perte en termes de comparabilité entre les tranches décennales notamment en taille de textes (et de mots).
Le tableau ci-dessous récapitule les différents niveaux et versions du corpus.
|
Niveaux Versions |
Noyau |
Contrôlé |
Étendu |
|
textes échantillonnés |
53 textes | 1.924.532 mots |
162 textes | 5.358.382mots |
315 textes | 11.002.199 mots |
|
textes intégraux |
53 textes | 6.820.161 mots |
162 textes | 11.636.573 mots |
315 textes | 28.309.240 mots |
Tableau 2
Récapitulatif des niveaux et des versions du corpus intégral Presto.
Les « descripteurs » dans le corpus Presto
Il est impératif de documenter les corpus. Concernant Presto, voici quelques informations relatives au jeu des métadonnées attaché aux textes du corpus.
Ces métadonnées sont pour l’instant structurées autour de deux grands niveaux hiérarchiques : l’œuvre et l’exemplaire. L’exemplaire correspond à la réalisation matérielle d’une œuvre de l’esprit, via une édition ou un manuscrit, en l’occurrence celle utilisée dans le corpus.
Relèvent de l’œuvre les informations relatives à l’auteur, et de l’exemplaire, celles relatives à l’éditeur scientifique. Ce schéma minimal pourra être complexifié par la suite pour permettre la prise en compte du paratexte (préface, postface, etc.).
A ces quatre entités sont associées un ensemble de métadonnées que nous avons séparées entre métadonnées « minimales », qui doivent obligatoirement être recherchées et vérifiées pour tous les textes du corpus (et donc renseignées lorsqu’elles existent), et les métadonnées « maximales », qui ne seront pas obligatoirement renseignées et/ou vérifiées.
Population cible, stratification, échantillonnages et tailles du corpus
Dans cette section, on restreindra le propos au seul corpus Prestocontrôlé version échantillonnée) dans la mesure où c’est sur lui qu’a porté l’essentiel de nos efforts en matière de construction du corpus.
Population
Population visée : nous avons choisi de définir la population du corpus suivant un critère de genres discursifs, plus précisément de « champ générique ». Ainsi avons-nous échantillonné pour la période 1501-1944 :
– trois « champs génériques » (au sens de F. Rastier 2011) relevant du discours littéraire (ibid.), à savoir i) les genres narratifs (romans, nouvelles, contes, …), ii) la poésie et iii) le théâtre.
– un « champ générique » (étiqueté comme tel par Frantext mais dont il reste à éprouver le bien-fondé), celui des « traités », qui s’avère « trans-dicours » puisqu’il peut s’agir de traités relevant des discours religieux, historiques, philosophiques, …
Le paramètre majeur qui a guidé le choix d’une telle population a été celui de la comparabilité entre tranches temporelles de dix ans, empan temporel que nous nous sommes fixés pour la structure temporelle interne de notre corpus.
Définition « opérationnelle » de la population (voir Biber 1993 & supra) : le projet soumis à l’ANR et la DFG déclarait sa volonté de coopérer avec les bases textuelles existantes que sont Frantext (http://www.frantext.fr, V. Montémont, G. Souvay), les BVH (Bibliothèques Virtuelles Humanistes, http://www.bvh.univ-tours.fr – L. Bertrand, M.-L. Demonet), l’ARTFL (American and French Research on the Treasury of the French Language, http://artfl-project.uchicago.edu – R. Morrissey, M. Olsen) et plus marginalement le CEPM (Corpus électronique de la première modernité, http://www.cpem.paris-sorbonne.fr). La liste des textes sur laquelle nous avons opéré nos échantillonnages a été la liste agrégée des textes mis à disposition par ces différentes bases.
Stratification
Nous avons adopté telles quelles les catégories génériques qui nous ont été communiquées par les bases citées ci-dessus. Autrement dit, aucun travail de définition des (sous-)genres n’a été conduit. Un tel travail – de première importance – demeure donc à faire, en bénéficiant notamment des réflexions menées par le groupe « typologie textuelle» dans le consortium CAHIER (https://cahier.hypotheses.org/groupe-typologie-textuelle).
Taille du corpus
Le nombre de mots pour chaque texte, le nombre de mots et de textes pour chaque champ générique, le nombre de mots total du corpus ont été fixés sans que nous ayons les moyens ni le temps de construire des procédures d’optimisation telle que celles conçues par exemple par D. Biber.
Pour nous donner un cap, nous sommes adossés à l’objectif de recherche linguistique déclaré dans Presto, à savoir l’étude des prépositions en diachronie. Il s’agit là d’une des catégories morphosyntaxiques les plus fréquentes dans tous les siècles de notre corpus (elle figure parmi les common linguistic features) et il paraît raisonnable de faire l’hypothèse que, comme en anglais contemporain (voir Biber), elles possèdent une distribution linéaire stable dans les textes et que, si leur distribution varie certainement suivant les genres, cette variation est moindre que pour des traits linguistiques rares.
Pour ce qui concerne les choix de taille en nombre de mots que nous avons faits pour l’échantillonnage des textes, les deux diagrammes ci-dessous permettent de visualiser successivement i) le nombre de mots par tranche décennale dans le corpus, ii) le nombre de mots par siècles. Rappelons que le diagramme 1 supra présente le nombre de textes par tranche décennale.
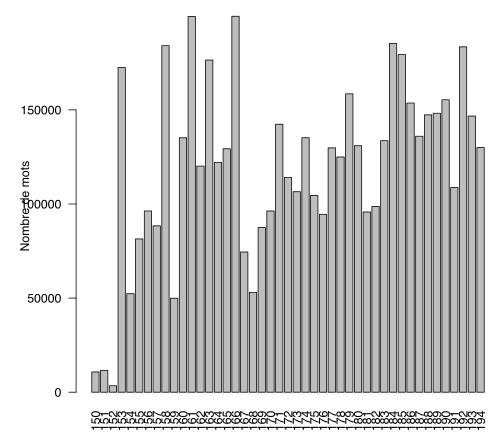
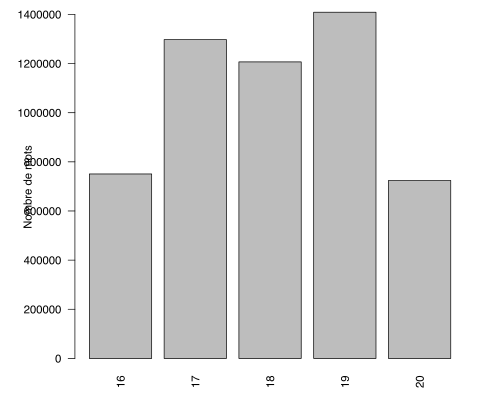
Il est aisé d’observer dans le diagramme 4 une faiblesse particulièrement sensible du nombre de mots pour les trois premières tranches décennales. Le diagramme 5 met quant à lui en lumière une disparité du XVIe et du XXe s. (toujours en termes de taille de mots) vis-à-vis des trois autres siècles. Il y a deux raisons distinctes à cette situation.
La taille du corpus XXe s. est d’environ la moitié de celle du XIXe s. pour une raison simple : il ne réunit que cinq décennies. Autrement dit, les principes d’échantillonnage ont été respectés pour ce corpus qui possède la même taille que les autres demi-siècles (excepté le XVIe s.).
Concernant le XVIe s. et notamment les trois premières décennies, le critère de comparabilité et les autres contraintes que nous nous étions fixées (droits juridiques, qualité philologique des textes) nous ont conduits à disposer d’une liste extrêmement réduite de textes candidats rendant impossible tout échantillonnage. La solution pour améliorer cette partie du corpus passera par trois voies qu’il conviendra de conjuguer : i) numériser de nouveaux textes, ii) éclaircir avec nos bases partenaires le statut juridique « flou » de certains textes dont on peut raisonnablement penser qu’ils ne sont plus sous droits et qu’ils pourraient être versés dans notre corpus, iii) rechercher dans Wikisource des textes numérisés et relus au moins par deux personnes et dont la qualité philologique s’approche au mieux de nos exigences.